Sémantický web
V dnešní době rychle rostoucího množství webových dokumentů nastává potřeba tato data uspořádávat a mít možnost je dále zpracovávat. Současný web poskytuje v tomto ohledu jen velmi omezené možnosti. Tuto problematiku má za úkol řešit sémantický web, kde se všechny informace definují takovým způsobem, aby jim porozuměli nejen lidé, ale i stroje. Tím je umožňována lepší spolupráce mezi počítači a lidmi a takto definovaná data je počítač schopen automaticky zpracovávat.
Úvod
Sémantický web [1, 2] přináší revoluci ve vytváření webu. Veškeré informace jsou zde definovány tak, aby jim porozuměli nejen lidé, ale i počítače, čímž je umožněna lepší spolupráci mezi počítači a lidmi. Nejedná se tedy o samostatný web, ale o rozšíření a zdokonalení toho současného.
Sémantický web přináší strukturu k vytvoření smysluplného obsahu webových stránek vytvářením prostředí, kde mohou potulující se softwaroví agenti snadno uskutečňovat sofistikované požadavky uživatele. Sémantický web není však pouze nástrojem pro provádění jednotlivých úkolů. Pokud je správně navržen, může pomoci při vývoji lidského poznání jako celku. [3]
Lidské úsilí se neustále potýká s problémem skloubení jednání malých nezávislých skupin a potřeby shodovat se s širší společností. Malá skupina může sice rychle a efektivně inovovat, ale tyto inovace nejsou obvykle chápany ostatními. Spolupráce v rámci velké skupiny je zase oproti tomu bolestně pomalá a vyžaduje obrovské množství komunikace. Je proto potřeba nějakým způsobem propojit práce menších skupin a umožnit sdílení dat mezi nimi pomocí rozšířenějšího běžného jazyka. Toto přesně si klade za cíl sémantický web.
Sémantický web umožňuje každému uživateli vytvořit nový pojem s poměrně minimálním úsilím. Všechny pojmy jsou označeny pomocí unikátních identifikátorů a díky sjednocujícímu logickému jazyku sémantického webu mohou být tyto pojmy postupně připojovány k univerzálnímu webu. Celý tento systém nám poskytuje mocný nástroj, pomocí kterého můžeme žít, pracovat a učit se společně.
Jednou z představ tvůrců sémantického webu je též to, že by se jednou mohl vymanit z virtuální říše a stát se součástí našeho fyzického světa. Identifikátory používané při tvorbě sémantického webu mohou odkazovat prakticky na cokoli, včetně například fyzických osob. Technologie sémantického webu pak můžeme použít například k popsání různých zařízení, jako jsou mobilní telefony či televizory. To, co nazýváme domácí automatizací, potřebuje dnes pečlivou a složitou konfiguraci pro dosažení spolupráce mezi aplikacemi. Pokud by byly schopnosti a funkce zařízení popsány sémanticky, dosáhli bychom takové automatizace s minimálním lidským zásahem.
Sémantika na webu
Název "sémantický web" souvisí se sémantikou, což je pojem pocházející původně z lingvistiky, který zde znamená nauku o významu slov a znaků, popřípadě jejich vztahu ke skutečnosti, kterou označují. Při tvorbě webu je sémantika velice důležitou veličinou, neboť právě díky ní jsou stroje schopné porozumět kódu stránky. Při tvorbě webových stránek pomocí jazyků HTML či XHTML se veškeré informace posílané na web obalují do speciálních značek, správně označovaných jako elementy. Některé tyto elementy mají přiřazen určitý význam a sémantika je právě o správném užívání těchto elementů na příslušných místech. Problém je však v tom, že ne všech HTML a XHTML značek se sémantika týká. Navíc lze u všech pomocí technologie kaskádových stylů upravovat jejich vlastnosti, takže i když výsledný vzhled stránky je pro člověka přehledný a čitelný, sémantika je špatná a stroj kódu nerozumí správně.
Sémantický web umožňuje strojům, aby rozuměly sémantice - tedy významu informací na World Wide Webu. To je důležité především pro vyhledávací roboty nebo například pro hlasové čtečky. Je však důležité si uvědomit, že sémantický web umožní strojům pochopit sémantické dokumenty a data, nikoli lidskou řeč a spisy.
Počátky sémantického webu
Myšlenka sémantického webu byla poprvé veřejnosti předvedena 17. května 2001, kdy v časopise Scientific American vyšel článek The Semantic Web. [3] Autory tohoto článku byli Tim Berners-Lee, vynálezce World Wide Webu a ředitel konsorcia W3C, James Hendler, jehož oborem je především umělá inteligence, a Ora Lassila, finský informatik zabývající se myšlenkou sémantického webu od roku 1996. Autoři článku upozorňují na problematiku stávajícího webu, jež obsahuje jen rychle narůstající množství dokumentů, které téměř postrádají informace, aby mohly být pochopitelné nejen člověkem, ale i stroji, a mohly tak být spravovány automaticky. Počítače jsou dnes v pro ně srozumitelně napsaném HTML či XHTML kódu schopné rozpoznat, která část kódu je hlavička či nadpis. Poznají též například, zda se jedná o odkaz na jinou webovou stránku, ale již nepoznají, na co konkrétně daný odkaz odkazuje. Sémantický web by měl toto napravit.
Autoři článku z roku 2001 [3] se snaží myšlenku sémantického webu vysvětlit na příkladu ze života. Představme si situaci: v místnosti hlasitě vyhrává píseň "We can work it out" od skupiny Beatles, když její melodii náhle přeruší zvonění telefonu. Ve chvíli, kdy majitel telefonu Petr hovor přijímá, pošle se zpráva všem ostatním přítomným zařízením, která ovládají nastavení hlasitosti, aby se hudba ztlumila. Petrovi volá jeho sestra Lucie od doktora: "Mamka potřebuje navštívit specialistu a poté musí jednou za čtrnáct dní podstupovat fyzioterapeutické sezení. Nastavím svému agentovi schůzky." Petr okamžitě souhlasí s podílem na dopravě.
V ordinaci Lucie mezitím dává instrukce agentovi svého sémantického webu pomocí ručního webového prohlížeče. Agent okamžitě získává informace o matčině předepsané léčbě od doktorova agenta, prohledá několik seznamů poskytovatelů a zkontroluje ty, kteří vyhovující matčinu pojištění, sídlí ve vzdálenosti do dvaceti mil od jejího domu a kteří mají vynikající nebo velmi dobré hodnocení na důvěryhodných zdrojích. Poté se snaží najít shodu mezi jejich časovou dostupností (poskytovanou agenty jednotlivých poskytovatelů prostřednictvím jejich webových stránek) a Petrovým a Luciiným nabitým rozvrhem.
Během několika minut agent představuje svůj plán. Petrovi se však nelíbil, neboť doporučená univerzitní nemocnice je přes celé město od matčina bytu a navíc by musel cestou zpátky řídit uprostřed dopravní špičky. Zadává tedy svému vlastnímu agentovi, aby opakoval hledání s přesnějšími požadavky na místo a čas. Luciin agent, kterému Petrův agent v rámci tohoto úkolu naprosto důvěřuje, pomáhá automaticky s dodáváním přístupu k certifikátům a zkratkám k datům, kterými se již sám probíral.
Téměř okamžitě je navrhnut nový plán, který nabízí mnohem bližší kliniku a o něco dřívější čas. Jsou zde však dvě varování. Za prvé by Petr musel přesunout některé své méně důležité schůzky, což nakonec uznává, že nebude problém. Za druhé, agent upozorňuje na to, že nalezený poskytovatel není zařazen mezi fyzioterapeuty na seznamu pojišťovny, byl však prověřen jinými prostředky. Dále agent nabízí Petrovi možnost podívat se na podrobnosti. Lucie souhlasí zhruba ve stejnou chvíli, kdy Petr mumlá: "Ušetři mě detailů," a tím je celá záležitost vyřešena. (Samozřejmě Petr nakonec neodolá prozkoumání detailů a později toho večera mu jeho agent vysvětluje, jak našel poskytovatele, i když nebyl na vyhovujícím seznamu.)
Petr a Lucie mohli použít své agenty k provedení všech těchto úkolů ne díky dnes stále nejvíce rozšířenému World Wide Webu, ale právě díky webu sémantickému, který by se měl do budoucna více rozvíjet.
Ontologie a slovníky
Jedním z často zmiňovaných pojmů v souvislosti se sémantickým webem je pojem "ontologie". [4-6] Ve filosofii označuje tento pojem teorii o povaze bytí, o tom, jaké typy věcí existují. Jako vědní disciplína studuje ontologie mnoho věcí.
Lidé zabývající se umělou inteligencí a vývojáři webových aplikací si tento pojem také zařadili do svého žargonu. Ontologie je pro ně dokument nebo soubor, který formálně definuje vztahy mezi pojmy. Nejběžnější typ ontologie pro web v sobě zahrnuje taxonomii a soubor odvozovacích pravidel. Taxonomie definuje třídy objektů a jejich vztahy. Třídy, podtřídy a vztahy mezi objekty představují pro uživatele webu velmi silný nástroj. Přiřadíme-li třídám určité vlastnosti a zároveň povolíme podtřídám tyto vlastnosti dědit, můžeme mezi objekty vyjádřit obrovské množství vztahů. Odvozovací pravidla pak poskytují další sílu v ontologii. I když počítač nemůže doopravdy rozumět žádným poskytovaným informacím, dokáže s nimi dnes pracovat mnohem efektivněji, a to způsoby, které jsou pro člověka užitečné a smysluplné.
S ontologií na webu se začínají konečně objevovat řešení problémů jak s terminologií, tak i různých dalších. Význam pojmů nebo XML kódů používaných na webových stránkách může být nyní definován pomocí ukazatelů ze stránek na ontologii.
Ontologie v mnoha směrech výrazně vylepšují a rozšiřují fungování webu. Například mohou být jednoduchým způsobem použity ke zvýšení přesnosti webových vyhledávačů. Vyhledávací program díky nim může vyhledat pouze ty stránky, které přesně odpovídají danému pojmu, místo toho, aby prohledával všechny, které v sobě používají nejednoznačná klíčová slova. Pokročilejší aplikace pak mohou ontologie využívat k propojení informací na stránce do struktur souvisejících znalostí a odvozovacích pravidel.
V souvislosti s ontologií se často vyskytuje i pojem "slovníky", anglicky vocabularies. Ty na sémantickém webu definují pojmy a vztahy používané k popisu a reprezentaci oblasti zájmu. Slovníky jsou používány ke klasifikaci pojmů, které mohou být použity ve speciální aplikaci, charakterizovat možné vztahy a vymezit případná omezení používání těchto pojmů. V praxi mohou být slovníky velmi komplexní a mohou obsahovat tisíce pojmů, nebo jsou velmi jednoduché a popisují například jen jeden či dva pojmy.
Rozdíl mezi termíny "slovníky" a "ontologie" není přesně vymezen, avšak všeobecným trendem je používání slova "ontologie" spíše pro mnohem komplexnější a možná i formálnější soubor pojmů. "Slovníky" jsou pak používány především tehdy, pokud některý striktní formalismus nemusí být nutně používán nebo je používán jen ve velmi volném smyslu.
Slovníky jsou základními stavebními kameny řídících technik na sémantickém webu. Slovníky jsou na sémantickém webu důležité především kvůli pomoci při propojení dat, například pokud by se mohly vyskytovat nějaké nejasnosti v pojmech používaných v různých datových souborech nebo kdyby nějaké další poznatky mohly vést k objevu nových vztahů.
Příkladem praktického využití slovníků je organizace znalostí. Knihovny, muzea, noviny, vládní portály, podniky, aplikace sociálních sítí a další společnosti, které spravují velké sbírky knih, historických artefaktů, zpravodajství, obchodní rejstříky, blogy a další jiné artikly, mohou dnes používat slovníky využívající standardní formalismy, aby ovlivnily sílu tzv. linked data. Linked data [7-9], česky propojená data, představují v dnešní době poměrně populární pojem, který v sobě zahrnuje způsob, jak publikovat data na webu tak, aby bylo možné je propojit a stala se tak užitečnějšími. Jedná se o velice podstatnou součást sémantického webu, který je vlastně webem těchto dat.
Jak obsáhlý slovník je třeba použít, záleží vždy na požadavcích a cílích aplikace. Některé aplikace se mohou spoléhat na logiku aplikačního programu a malé slovníky vůbec nemusejí využívat. Jiné aplikace mohou využívat velmi jednoduché slovníky a mohou nechat hlavní prostředí sémantického webu, využívající těchto extra informací, vytvářet identifikaci pojmů. Některé aplikace potřebují dohodu o běžných terminologiích, bez přísností předepsaných logickým systémem. Některé aplikace mohou vyžadovat obsáhlejší ontologie s komplexními postupy uvažování.
Agenti
V původním článku o sémantickém webu z roku 2001 [3] autoři předpokládají, že skutečná síla sémantického webu bude realizována teprve tehdy, až lidé vytvoří větší množství programů, které shromáždí webový obsah z různých zdrojů, zpracují získané informace a vymění si výsledky s dalšími programy. Účinnost těchto softwarových agentů [10] podle autorů článku poroste exponenciálně, jak bude k dispozici více a více informací pro stroje čitelného webového obsahu a automatizovaných služeb (včetně dalších agentů). Sémantický web prosazuje, aby i agentům, kteří nejsou výslovně určeni pro spolupráci, bylo umožněno přenášet mezi sebou data, pokud tato data obsahují sémantiku.
Důležitým aspektem fungování agentů je výměna důkazů psaných v jednotném jazyce sémantického webu. Tím je myšlen jazyk, který vyjadřuje logické závěry vytvořené použitím pravidel a informací, jako jsou ty stanovené v ontologiích.
Další důležitou funkcí jsou digitální podpisy, které jsou šifrovanými bloky dat, jež mohou počítače a agenti používat k ověření důvěryhodnosti konkrétního zdrojem. Agenti by měli být skeptičtí k tvrzením, která čtou na sémantickém webu, dokud je nezkontrolují pomocí více důvěryhodných zdrojů informací.
Agenti na sémantickém webu si mohou navzájem porozumět díky výměně ontologií, které poskytují potřebné slovníky. Agenti mohou dokonce, pokud objeví nové ontologie, sami zavádět nové logické schopnosti.
Technologie sémantického webu
V původním dokumentu o sémantickém webu [3] jsou pro jeho vytváření navrhovány dvě technologie: XML (eXtensible Markup Language) a RDF (Resource Description Framework). Spojením těchto dvou technologií pak vzniká jeden ze základních jazyků pro zapisování informací na sémantickém webu RDF/XML.
V dnešní době existuje poměrně velké množství alternativ RDF/XML, které jsou na tomto formátu založeny a které ho doplňují a rozšiřují. Mezi nejdůležitější patří například RDFS (RDF Schema), OWL (Web Ontology Language), SKOS (Simple Knowledge Organization System) či Turtle (Terse RDF Triple Language).
Zvláštní postavení mezi technologiemi používanými na sémantickém webu má pak dotazovací jazyk SPARQL, což je jazyk navržený speciálně pro vytváření dotazů na RDF.
Vrstvy sémantického webu
Základní principy sémantického webu lze rozdělit do jednotlivých vrstev webových technologií a standardů [11], jak je možno vidět na obrázku níže.
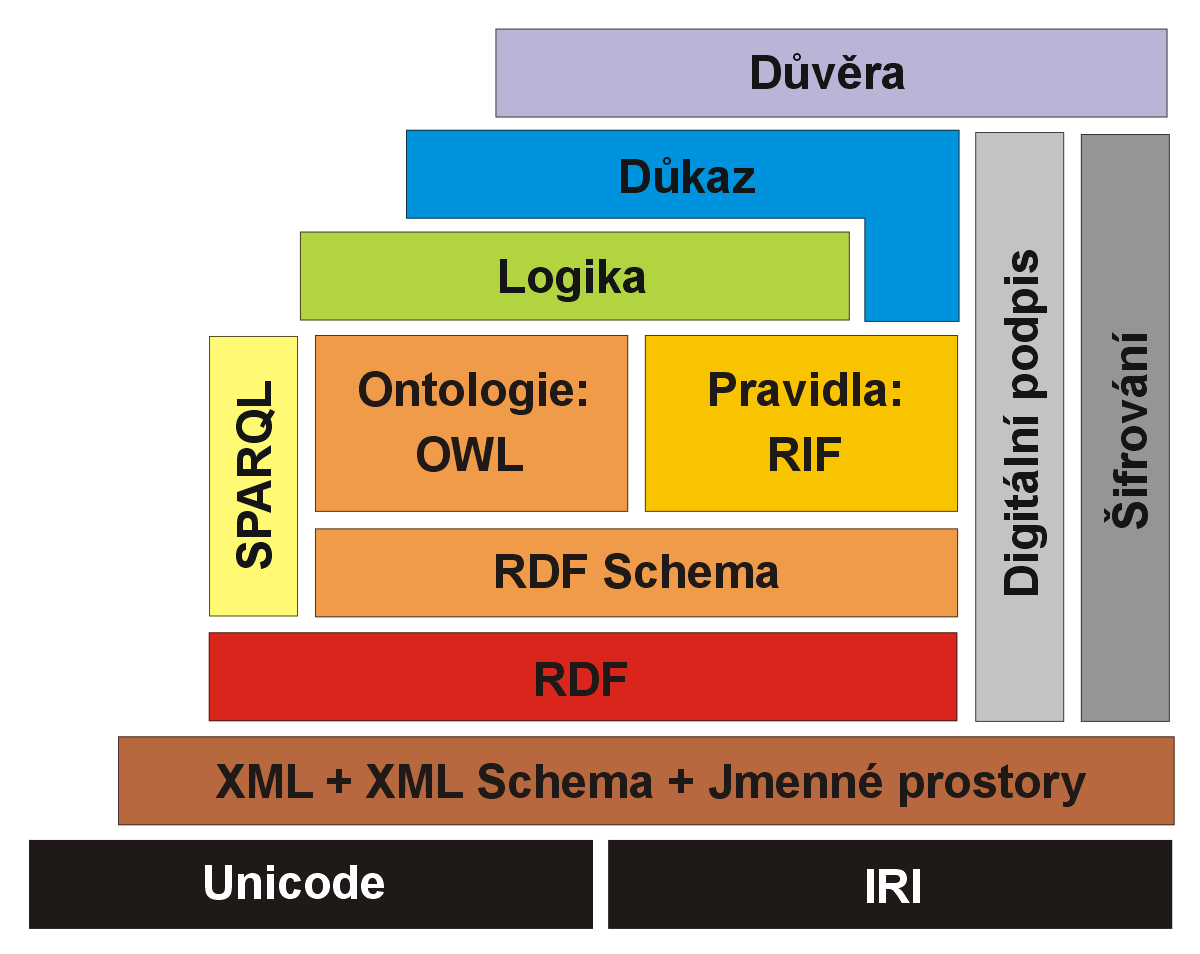
Obrázek 1: Vrstvy sémantického webu
Toto schéma ilustruje architekturu sémantického webu a nazývá se The Semantic Web Stack (česky Zásobník sémantického webu), někdy též Semantic Web Cake (Dort sémantického webu) či Semantic Web Layer Cake (Vícevrstevný dort sémantického webu). [12-14] Jednotlivé vrstvy se postupně snaží vyřešit a standardizovat konsorcium W3C [15].
Spodní vrstva schématu nám určuje, že základem celého sémantického webu, i webu současného, je užívání mezinárodní znakové sady Unicode, která obsahuje znaky všech abeced světa, a identifikování jednotlivých objektů pomocí IRI (Internationalized Resource Identifier), které v současné době nahrazuje známější URI (Universal Resource Identifier). URI i IRI jsou dnes definována RFC 3986 [16]. Rozdíl mezi URI a IRI spočívá v tom, že URI smí obsahovat pouze ASCII znaky, zatímco v IRI je možno použít libovolné znaky Unicode. Používání znakové sady Unicode a identifikátorů v podobě IRI je dnes již běžnou ustálenou praxí, kterou programátoři akceptují a obvykle dodržují.
Díky další vrstvě zahrnující značkovací jazyk XML, XML Schema a jmenné prostory, anglicky Namespaces, máme zaručeno, že můžeme jednotlivé popisy na sémantickém webu zapisovat ve standardech založených na jazyce XML. Jmenné prostory velice napomáhají čitelnosti dokumentu a jsou uvedeny vždy na jeho začátku uzavřené do rdf:RDF. Jmenné prostory si můžeme též sami vytvářet:
<rdf:RDF
xmlns:info="http://www.motejlka.cz/info#" > ,
zároveň existují i předdefinované jmenné prostory:
<rdf:RDF
xmlns:rdf = "http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:rdfs = "http://www.w3.org/2000/01/rdf-schema#"
xmlns:owl = "http://www.w3.org/2002/07/owl#"
xmlns:skos = "http://www.w3.org/2004/02/skos/core#"
xmlns:dc = "http://purl.org/dc/elements/1.1/"
xmlns:foaf = "http://xmlns.com/foaf/0.1/"
xmlns:geonames = "http://www.geonames.org/ontology#"
xmlns:xsd = "http://www.w3.org/2001/XMLSchema#" > .
Jakousi nadstavbou XML je technologie RDF. Ta určuje, že vše na sémantickém webu musí mít přidělen identifikátor v podobě IRI. Na rozdíl od RDF při psaní XML nemusí být toto pravidlo dodržováno. Z tohoto důvodu není podmínka identifikace pomocí IRI splňována na současném webu psaném pomocí HTML, které z XML vychází.
Na principu RDF jsou založeny veškeré další technologie pro vytváření sémantického webu. Mezi ty základní patří dotazovací jazyk SPARQL, RIF (Rule Interchange Format) [17] pro vytváření pravidel na sémantickém webu a ontologické struktury RDF Schema a OWL, které definují slovníky pro interpretaci sémantiky informací a díky nimž je možné odvozovat další informaci aplikováním použitelné logiky.
Velice důležitou součástí dokumentů na webu jsou dále digitální podpisy a šifrování. Ty zajišťují důvěryhodnost a autenticitu jednotlivých dokumentů. Díky digitálnímu podpisu se dají též snadno detekovat případné změny v dokumentu.
Vrchní vrstvy logika a důkaz nejsou prozatím vyřešenou a uzavřenou záležitostí a skupiny pracovníků z W3C na nich stále pracují. Logika na sémantickém webu slouží k automatickému odvozování informací z ontologií a sémantických dat. Díky důkazu by pak mělo být možno přesně určit, zda jsou získané informace pravdivé.
Vrstvou zastřešující všechny ostatní je důvěra. Té bude moci být dosaženo teprve tehdy, až budou vyřešeny všechny ostatní vrstvy.
- W3C, W3C Semantic Web Activity. 2011. Dostupné z adresy: http://www.w3.org/2001/sw/.
- W3C, Semantic Web.
- Berners-Lee, T., J. Hendler, and O. Lassila, The Semantic Web. Scientific American, 2001. 284(5): p. 34-+. ISBN: 0036-8733.
- Gruber, T.R., A TRANSLATION APPROACH TO PORTABLE ONTOLOGY SPECIFICATIONS. Knowledge Acquisition, 1993. 5(2): p. 199-220. ISBN: 1042-8143.
- Uschold, M. and M. Gruninger, Ontologies: Principles, methods and applications. Knowledge Engineering Review, 1996. 11(2): p. 93-136. ISBN: 0269-8889. DOI: 10.1017/S0269888900007797.
- W3C, Vocabularies. Dostupné z adresy: http://www.w3.org/standards/semanticweb/ontology.
- Berners-Lee, T., Linked Data. International Journal on Semantic Web and Information Systems, 2006. 4(2): p. 1. ISBN: 15526283. DOI: 10.4018/jswis.2009081901.
- Bizer, C., T. Heath, and T. Berners-Lee, Linked Data - The Story So Far. International Journal on Semantic Web and Information Systems, 2009. 5(3): p. 1-22. ISBN: 1552-6283. DOI: 10.4018/jswis.2009081901.
- W3C, Linked Data. Dostupné z adresy: http://www.w3.org/standards/semanticweb/data.
- Huhns, M.N., Agents as Web services. Ieee Internet Computing, 2002. 6(4): p. 93-95. ISBN: 1089-7801. DOI: 10.1109/MIC.2002.1020332.
- Koivunen, M.-R. and E. Miller, W3C Semantic Web Activity. 2001. Dostupné z adresy: http://www.w3.org/2001/12/semweb-fin/w3csw.
- Eiter, T., et al., Reasoning with rules and ontologies, in Reasoning Web, P. Barahona, et al., Editors. 2006. p. 93-127. ISBN: 3-540-38409-X. DOI: 10.1007/11837787_4.
- Horrocks, I., et al., Semantic Web architecture: Stack or two towers?, in Principles and Practice of Semantic Web Reasoning, Proceedings, F. Fages and S. Soliman, Editors. 2005. p. 37-41. ISBN: 3-540-28793-0. DOI: 10.1007/11552222_4.
- Kifer, M., et al., A realistic architecture for the Semantic Web, in Rules and Rule Markup Languages for the Semantic Web, Proceedings, A. Adi, S. Stoutenburg, and S. Tabet, Editors. 2005. p. 17-29. ISBN: 3-540-29922-X.
- World Wide Web Consortium. Dostupné z adresy: http://www.w3.org/.
- Berners-Lee, T. (2005) Uniform Resource Identifier (URI): Generic Syntax. Dostupné z adresy: http://tools.ietf.org/html/rfc3986.
- RIF Overview, M. Kifer and H. Boley, Editors. 2010, W3C.Dostupné z adresy: http://www.w3.org/TR/rif-overview/.
Máme zde 1 komentář
Chyby
Text bohužel obsahuje hodně zavádějících informací. Například:
- RDFS, SKOS a OWL nejsou alternativy k RDF/XML. Tou je z uvedených pouze Turtle. Jak RDF/XML, tak Turtle, jsou serializace (způsob zápisu RDF).
- RDF nemá s XML nic společného. Rozhodně nejde o "nadstavbu" XML. Je to pouze RDF/XML, jeden z možných způsobů zápisů RDF, který používá syntaxi XML.