Jazykové korpusy: Korpusy polského jazyka
Úvod
Na poli polské korpusové lingvistiky není situace až tak jednoznačná, neboť v Polsku vzniká hned několik korpusů nezávisle na sobě (více viz ŠULC, 2002). My se zaměříme na tři poměrně velké a zajímavé polské korpusy.
Nejdříve si představíme Korpus IPI PAN, který je vůbec prvním polským korpusem zveřejněmým na internetu (zpřístupněn vyl na serveru Ohijské státní uiverzity – The Ohio State University). Svou činností k tomu v roce 1999 dopomohl Adam Przepiórkowski. V současnosti je přístup k němu umožněn ze stránek Institutu základů informatiky Polské akademie věd (Instytut Podstav Informatyki Polskiej Akademii Nauk).
Dále se budeme věnovat Korpusu jazyka polského Vědeckého nakladatelství PWN, který začal být budován v roce 1996. Zajímavé na něm je to, že vznikl z jazykového materiálu, který nakladatelství shromažďuje a zpracovává pro slovníky, na jejichž vydání pracuje.
Posledním dnešním představeným korpusem bude korpusový projekt PELCRA, který vznikl v roce 1997 na Univerzitě v Lodži ve spolupráci s Univerzitou v Lancasteru. Zajímavostí projektu je, že v něm vznikají hned čtyři různé korpusy, z nichž je nejzajímavějším (a na poli korpusové lingvistiky s velkou pravděpodobností ojedinělým) je Polský korpus studentů angličtiny.
Za zmínku ještě stojí, že první korpus polského jazyka začal vznikat v roce 1990 pod vedením prof. Irenusze Bobrowského na půdě Institutu polského jazyka Polské akademie věd. Zpočátku byl korpus tvořen s ohledem na plánované vydání slovníku polštiny, který měl navazovat na Doroszewskeho Słownik języka polskiego (největší slovník polštiny), od jehož tvorby se však časem upustilo. V roce 2002 obsahoval 16 milionů slov [ŠULC, 2002].
Korpus IPI PAN
Korpus jazyka polského IPI PAN (Korpus Języka Polskiego IPI PAN) obsahuje přes 250 milionů slov, je morfologicky anotovaný a veřejně přístupný. Vytvářen byl Linguistic Engineering Group Institutu počítačové vědy Polské akademie věd (ICS PAS).
Prohledávat jej lze pomocí programu Poliqarp, který je dostupný jako program běžící pod operačními systémy Windows i Linux (ke stažení je nabízen společně s ukázkovými verzemi korpusu), ale má i online vyhledávací rozhraní. Přístup do korpusu je bezplatný.
IPI PAN korpus byl společně s různými doprovodnými nástroji vytvořen hlavně během dvou národních projektů pod vedením Adama Przepiórkowského a uskutečněn na ICS PAS. Byly jimi The IPI PAN Corpus of Polish (2001–2004) a Automatic extraction of linguistic knowledge from a large corpus of Polish (2005–2007).
První vydání korpusu z června roku 2005 je na webových stránkách korpusu nabídnuto ke stažení hned v několika verzích. První subkorpus obsahuje přes 100 milionů výskytů korespondující s více než 286 tisící různých lemmat. Tento subkorpus byl vytvořen z úplného korpusu odstraněním všech novinových textů stejně jako 10 % náhodných odstavců každého textu. Druhý nabízený subkorpus je ukázkou korpusu dodávaného na CD s názvem The IPI PAN Corpus. Preliminary Version. Obsahuje více než 70 milionů výskytů s více než 364 tisíci různými lemmaty.
Třetí subkorpus dostupný také z WWW rozhraní obsahuje přes 15 milionů výskytů s více než 217 tisíci různými lemmaty. Textové zastoupení je téměř stejné jako u pozdějšího druhého vydání korpusu (viz níže). Všechny texty byly vytvořeny v průběhu posledních patnácti let, starší próza se sestává z textů napsaných koncem 19. a na počátku 20. století. Jejich přítomnost v korpusu je ospraveditelná jejich proslulostí ve školách.
Nejmenším nabízeným subkorpusem je Frekvenční slovník současné polštiny (Słownik frekwencyjny polszczyzny współczesnej) vytvořený v 60. letech a obsahující přes 500 tisíc slov rozdělených do pěti žánrů: populární věda, zprávy (news dispatches), komentáře a dlouhé články, umělecká próza a umělecké drama. Obohacenou verzí tohoto korpusu je Enriched Corpus of the Frequency Dictionary [1]. Corpus of the Frequency Dictionary (IPI PAN), tedy webová varianta Frekvenčního slovníku, byla přetagována podle tagů IPI PAN a kompletně ručně verifikována. Tento korpus se skládá z 662 tisíc výskytů korespondujících více než 35 tisíci různými lemmaty. Dostupný je také ve verzi XML.
Druhé vydání korpusu (z března roku 2006) je ke stažení v plné verzi, která obsahuje 250 milionů výskytů, nebo ve verzi o velikosti 30 milionů výskytů, která je rovněž k dispozici přes WWW rozhraní. Toto vydání obsahuje přes 10 % současné prózy, téměř 10 % starší prózy, 10 % naučné literatury, 50 % novinových článků, 15 % parlamentních sborníků a 5 % zákonů.
Webová prezentace
Webová prezentace korpusu IPI PAN je poměrně strohá a velice jednoduchá, úvodní stránka je rozcestníkem ke všem hlavním tématům (viz obr. 1) a zároveň stručně informuje o samotném korpusu (více informací se zobrazí po kliknutí na – z jistého pohledu nelogické – tlačítko Download). Autoři stručně informují o programu Poliqarp, zveřejňují bibliografické záznamy, případně i odkazy na online verze článků, které se týkají nejen IPI PAN korpusu. Součástí stránek je také poděkování všem, kdo se na tvorbě korpusu podíleli. Na úvodní stránce je také umístěno vstupní pole pro základní vyhledávání v korpusu s možností přímého vstupu k vyhledávání „pokročilému“.
Nedostatkem stránek je absence jakékoliv možnosti návratu na úvodní stránku z vyhledávacího rozhraní a v porovnání i s ostatními v textu dále zmíněnými korpusy i poměrně málo informací o projektu a korpusu samotném.
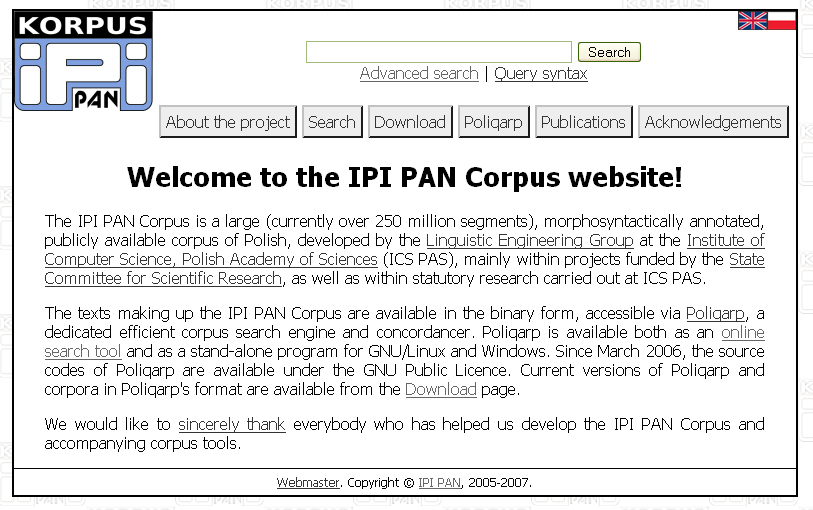
Obr. 1: Úvodní stránka Korpusu IPI PAN
Vyhledávání
Jak již bylo zmíněno, vstupní pole pro vyhledávání je přístupné přímo z hlavní stránky, pod ním je v nabídce i možnost pokročilého vyhledávání a odkaz Query Syntax. Pokročilé vyhledávání ve své základní verzi umožňuje jen výběr ze čtyř zpřístupněných korpusů (IPI PAN Corpus sample (2nd edition; 30M segments), Full IPI PAN Corpus (2nd edition; 250M segments), Frequency Dictionary Corpus (0,5M segments), IPI PAN Corpus sample (1st edition, obsolete; 15M segments).
Po kliknutí na tlačítko Show search options (viz obr. 2) se zobrazí možnosti třídění nalezených výsledků (např. podle kontextu zprava či zleva), způsob jejich zobrazení (např. jen segmenty a lemmata) a šíře kontextu. Nechybí ani možnost zvolit počet zobrazených výsledků na stránku.
Pod odkaz Query syntax se skrývá podrobný popis členění slov, tagování i vyhledávacího jazyka, kde jsou popsány možnosti vyhledávání pravopisných, základních tvarů, ale i tagů či omezení na věty a odstavce či použitá metadata. Pro vyhledávání lze použít i zástupné symboly (?, *, +, ., ,, |, {, }, [, ], (, )).
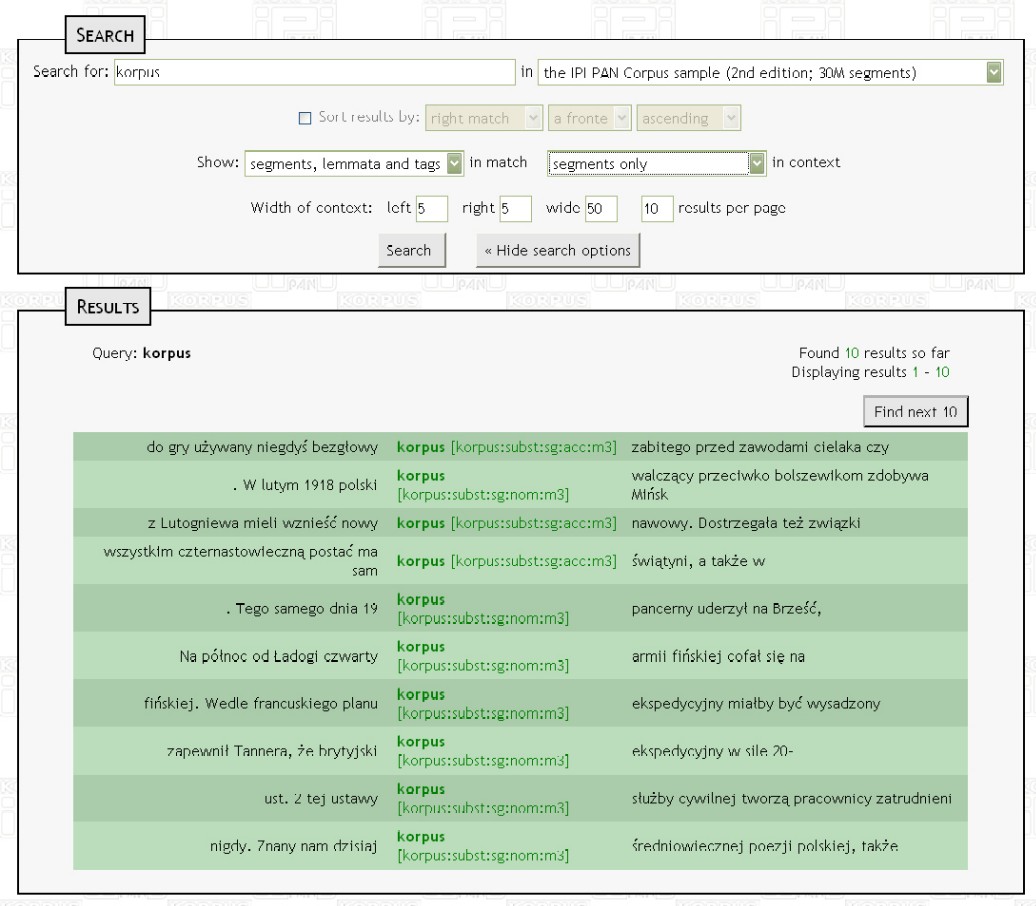
Obr. 2: Náhled výsledků vyhledávání slova korpus v Korpusu IPI PAN
Korpus Języka Polskiego Wydawnictwa Naukowego PWN
Korpus jazyka polského Vědeckého nakladatelství PWN je výběrem z původního jazykového materiálu pro slovníky, na kterých nakladatelství pracuje. Materiál v korpusu složí tvůrcům slovníků k popisu a doložení významů slov.
Online verze korpusu obsahuje 40 milionů slov. Příklady jsou brány z 386 knih, 977 edic vybraných ze 185 různých tištěných publikací, 84 transkribovaných mluvených textů, 207 webových stránek, několika stovek inzertních letáků a dalších dokumentů s krátkodobou platností. Úplná verze korpusu je však přístupná až po zaplacení poplatku. Do volně dostupné online verze je zahrnuto více než 7,5 milionů slov. Tato verze je i součástí CD s Univerzálním slovníkem polštiny (Uniwersalny słownik języka polskiego), na němž nakladatelství pracuje.
Snahou autorů je mít přiměřeně vyvážený korpus v zastoupených typech textů, v časovém pokrytí, regionu, věku a pohlaví autorů včetně tematické vyváženosti.
V porovnání s ostatními světovými korpusy obsahuje korpus PWN velký poměr literárních textů. To je dávno hlavně snahou autorů respektovat silnou polskou tradici, kdy jsou kulturní autority brány jako kritérium lingvistické správnosti. Z toho důvodu se jádro korpusu skládá převážně z klasické literatury 20. století (od prózy přes drama po poezii, což je na poli korpusů poměrně vzácnost).
V současnosti obsahuje korpus 70 milionů slov, avšak jako celek, tzn. včetně tiskového archivu a klasické středověké literatury obsahuje přes 100 milionů slov.
Webová prezentace
Stránky korpusu jsou součástí webové prezentace nakladatelství (viz obr. 3). Z hlavní stránky nakladatelství se lze na sekci týkající se korpusu dostat poklepem na odkaz polszczyzna a poté na odkaz korpus.
Sekce o korpusu je poměrně přehledně uspořádána, navigační položky jsou v pravém sloupci. Stránka obsahuje všechny důležité informace o korpusu, jeho vzniku, složení (včetně seznamu zastoupených knih a novin) i možnostech vyhledávání.
Přestože se může zdát začlenění stránek o korpusu do stránek nakladatelství ne zcela šťastným řešením, autoři si s tím dle mého názoru poradili velice dobře a přehledně.

Obr. 3: Úvodní stránka korpusu PWN
Vyhledávání
Do formuláře pro vyhledávání lze vstoupit z úvodní stránky korpusu poklepem na odkaz search in the corpus. Poměrně jednoduchý formulář (viz obr. 4) umožňuje prohledávat v náhodné části korpusu, jen v položkách novin Rzeczpospolita či v celém korpusovém materiálu (v případě volně dostupné verze jen ve zpřístupněném materiálu). Do pole pro vyhledávání lze zapsat slovo nebo frázi, velká a malé písmena nemají na výsledek vliv. Používat lze také zástupné znaky (* pro více písmen, ? pro jedno písmeno). Hledat lze také dvě slova či fráze najednou, musí však být oddělena lomítkem /. Kontextové vyhledávní je dostupné pouze u plné verze.
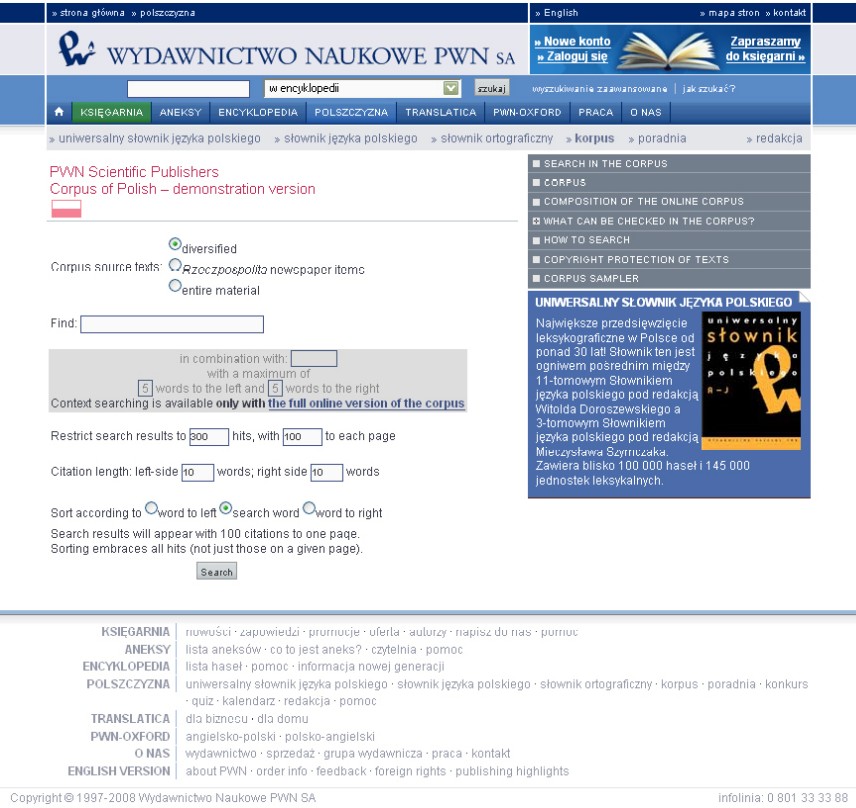
Obr. 4: Formulář pro vyhledávání v Korpusu PWN
Výsledky vyhledávání (viz obr. 5) jsou zobrazeny v tzv. konkordancích nebo seznamu všech výskytů daného slova. Před samotným hledáním má uživatel možnost nastavit si celkový počet zobrazených výskytů včetně jejich množství na stránce. Dále je možno nastavit šíři kontextu, a to zleva i zprava. Poslední nastavitelnou volbou je možnost seřazení výsledků hledání podle hledaného slova nebo podle prvního kontextového slova vpravo nebo vlevo. Vybrat lze i zdroj textů – různé, položky z novin Rzeczpospolita nebo kompletní materiál.

Obr. 5: Výsledky vyhledávání slova jazyk v Korpuse PWN (hledání bylo omezeno na texty z novin Rzeczpospolita se zobrazením deseti výsledků na stránku a zarovnáním podle levého kontextového slova)
PELCRA
Projekt PELCRA (Polish and English Language Corpora for Research and Applications) byl zahájen v roce 1997. Podílelo se na něm Oddělení anglického jazyka na Univerzitě v Lodži a Oddělení lingvistiky a moderního anglického jazyka na Lancasterské univerzitě. Cílem byla kompilace polštiny a moderní angličtiny v korpusu, a to jak pro výzkum, tak pro další lingvistické aplikace. Nyní projekt pokračuje na Univerzitě v Lodži. Po zalogování (heslo a uživatelské jméno je uvedeno na úvodní stránce) je možno ve zveřejněném korpusu vyhledávat.
PELCRA poskytuje obrovský zdroj pro akademický a technologický výzkum i pro praktické aplikace. Výstupem projektu jsou hned čtyři jazykové korpusy:
- Referenční korpus polštiny (The PELCRA Reference Corpus of Polish) je jako jediný dostupný online. Obsahuje soubor psaného a mluveného jazyka o celkové velikosti přes 100 milionů slov. Je navržen tak, aby reflektoval potřebu vytvořit referenční korpus polštiny pro výzkum a další lingvistické aplikace.
- Polský korpus studentů angličtiny (Polish Learner English Corpus) je jedním z klíčových v projektu. Jedná se o sbírku textů vytvořených studenty angličtiny od začátečníků po akademiky. V současnosti obsahuje 500 tisíc slov, ale jejich počet průběžně narůstá. Korpus by měl sloužit k identifikaci typických chyb v cizojazyčném textu, které jsou způsobeny rozdíly mezi oběma jazyka. Je to pokus o první krok nutný k vývoji odpovídajících výukových materiálů.
- Anglicko-polský paralelní a srovnávací korpus (Polish-English & English-Polish Parallel and Comparable Corpora) obsahuje jak polské materiály přeložené z a do angličtiny, tak nepřeložené autentické texty. Zahrnuje přeložené texty z různých zdrojů (časopisy, knihy) [2]. Jeho primární použití je pro konfrontační studia a překladatelskou práci. Tvůrci začali také pracovat na „výukovém překladu“ [3], což má být spojení mezi korpusem „studentským“ a paralelním.
- Polský multimediální korpus mluveného hovorového jazyka (Polish Spoken Conversational Mutimedia Corpus) je součástí referenčního korpusu polštiny. Je koncipován jako spontánní přirozená konverzace nahrávaná ve chvíli, kdy účastníci netuší, že jsou nahráváni. Získané nahrávky jsou pečlivě transkribovány a anotovány. Originální nahrávky jsou digitalizovány a komprimovány do formátu MP3. V současnosti korpus obsahuje 500 tisíc slov transkribovaného rozhovoru, což je více než 24 hodiny digitalizovaného záznamu.
Webová prezentace
Webové stránky projektu (viz obr. 6) jsou přehledné, i když se na první pohled mohou zdát poněkud složitějšími. Horizontální menu úvodní stránky umožňuje zvolit korpus, který se bude prohledávat (na výběr je referenční a mluvený korpus), obsahuje odkaz na korpusové novinky a BiT Dictionari, což je bilingvní tezaurus (polsko-anglický). Důležitým odkazem horizontálního menu je položka PELCRA, pod níž se skrývají stránky informující o celém projektu a zpracovávaných korpusech.
Menu levého sloupce nabízí výběr různých způsobů vyhledávání v korpusu (viz níže), je v něm navýběr možnost zobrazit frekvenci slov, metadata o autorech či textech atd. Všechny tyto položky jsou přístupné až po přihlásení se do korpusu. Formulář pro přihlášení se nachází v prostředním, hlavním sloupci, který navíc obsahuje informace o počtu slov, textů, autorů, vět a odstavců, součástí je též krátké uvítání. Pravý sloupec obsahuje pouze odkazy na vybrané korpusy a instituce.
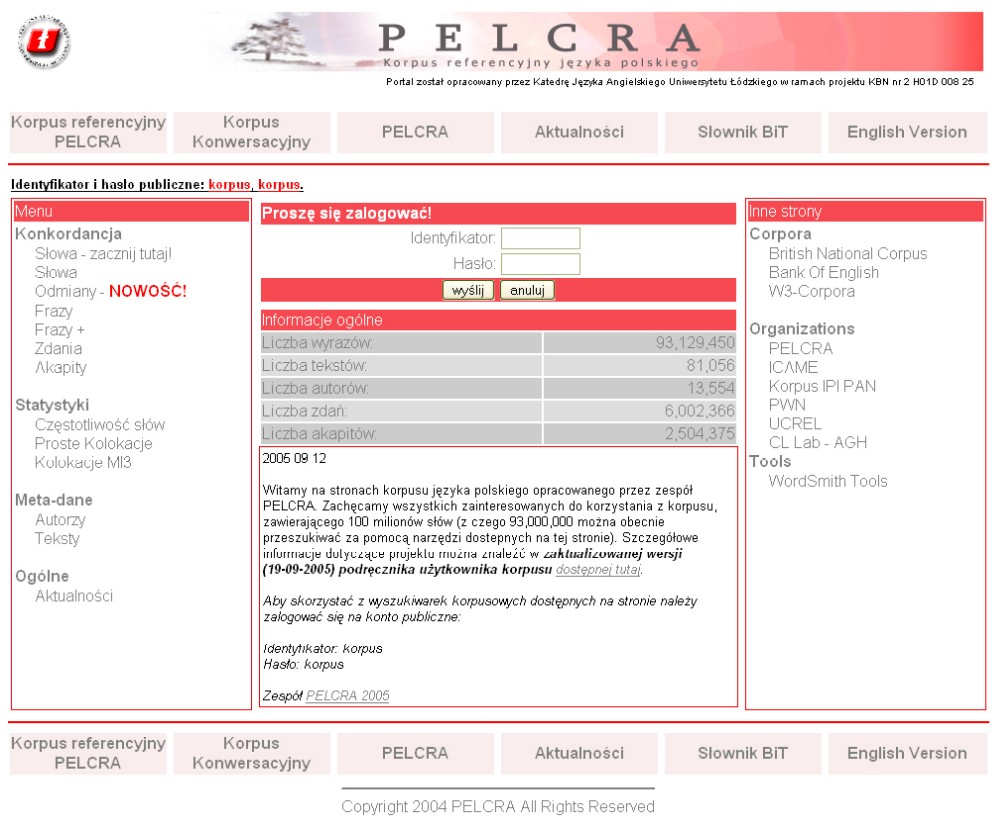
Obr. 6: Úvodní stránka projektu PELCRA
Vyhledávání
Vyhledávat v korpuse PELCRA je možné po přihlášení se do systému (heslo a uživatelské jméno je corpus). Vyhledávat lze jedno slovo (zvolit lze i možnost hledat všechny tvary daného slova), frázi, věty nebo celé odstavce. Po zvolení typu vyhledávání se zobrazí vyhledávací formulář (viz obr. 7), který je pro všechny typy víceméně stejný. Do vstupního pole lze zadat hledané slovo, frázy či slova, která mají být obsažená ve větě/odstavci. V případě hledání vět a ostavců lze zapsat i slova, která daná věta/odstavec nemá obsahovat.
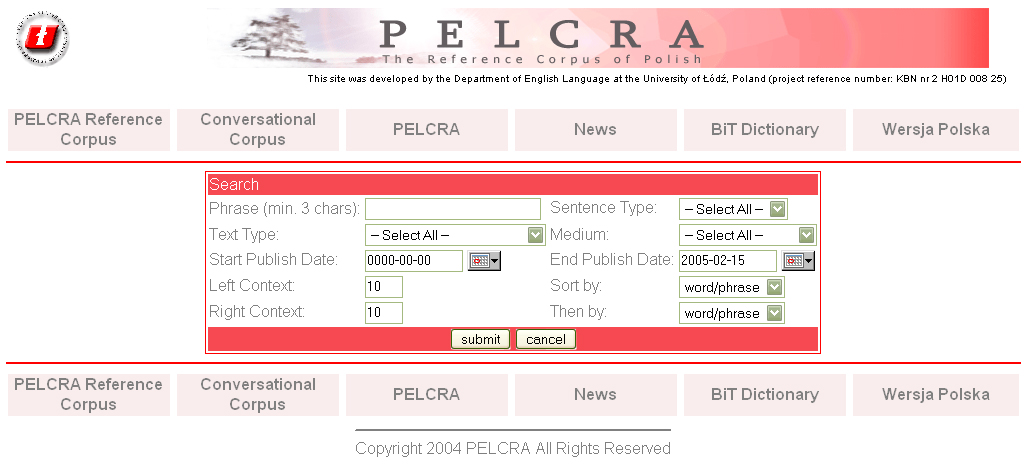
Obr. 7: Vyhledávací formulář pro hledání fráze
Hledání lze omezit podle typu textu (mluvený, psaný, hovorový), typu věty (oznamovací, tázací, zvolací a různé), typu nosiče (kniha, záznam, webová stránka, periodika aj.), data publikování a šíři kontextu. Nastavit lze též volbu srovnání zobrazených výsledků (podle kontextu, hledaného slova/fráze nebo zdrojového textu). Zástupné znaky nahrazuje nabídka Search Type, v níž lze nastavit, zda slovo obsahuje, začíná či končí zadanými znaky (v případě hledání vět/odstavců je zde volba hledání všech zadaných slov nebo jen některého).
Výstupy různých vyhledávání jsou zobrazeny na obr. 8 až 12.
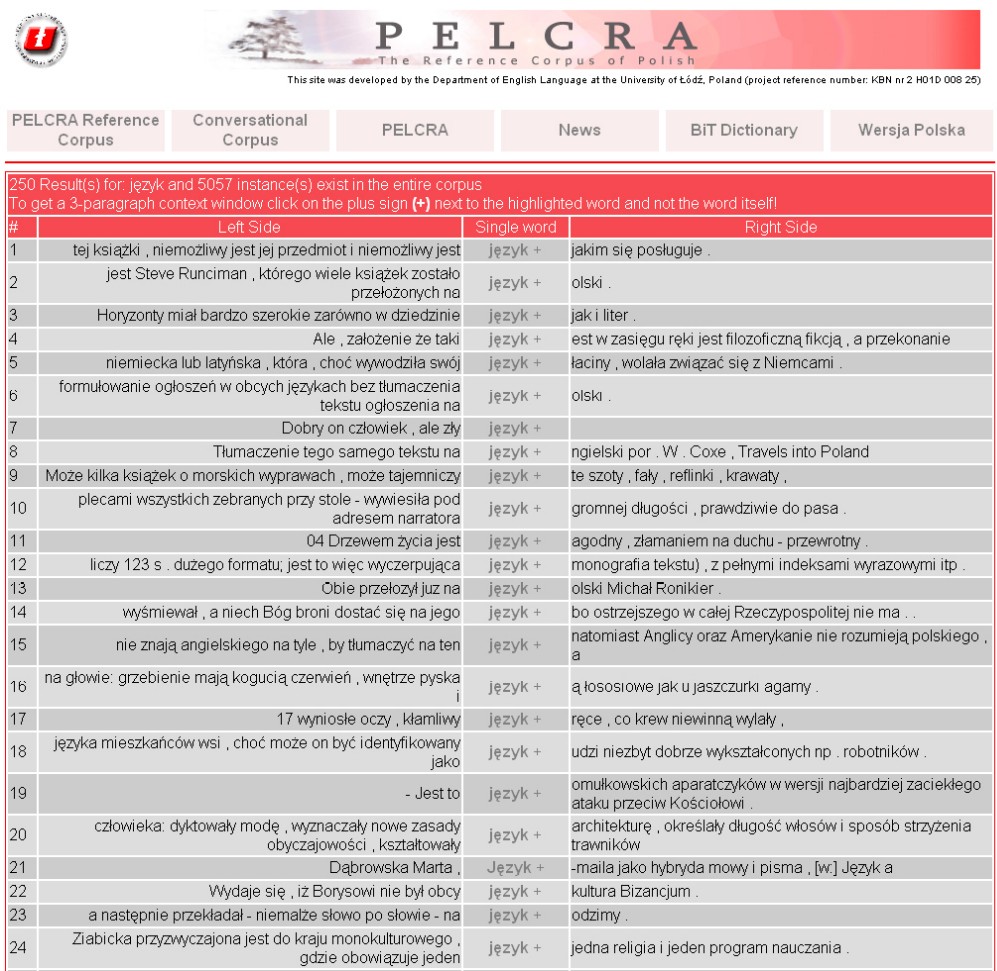
Obr. 8: Zobrazení výsledku vyhledávání slova język
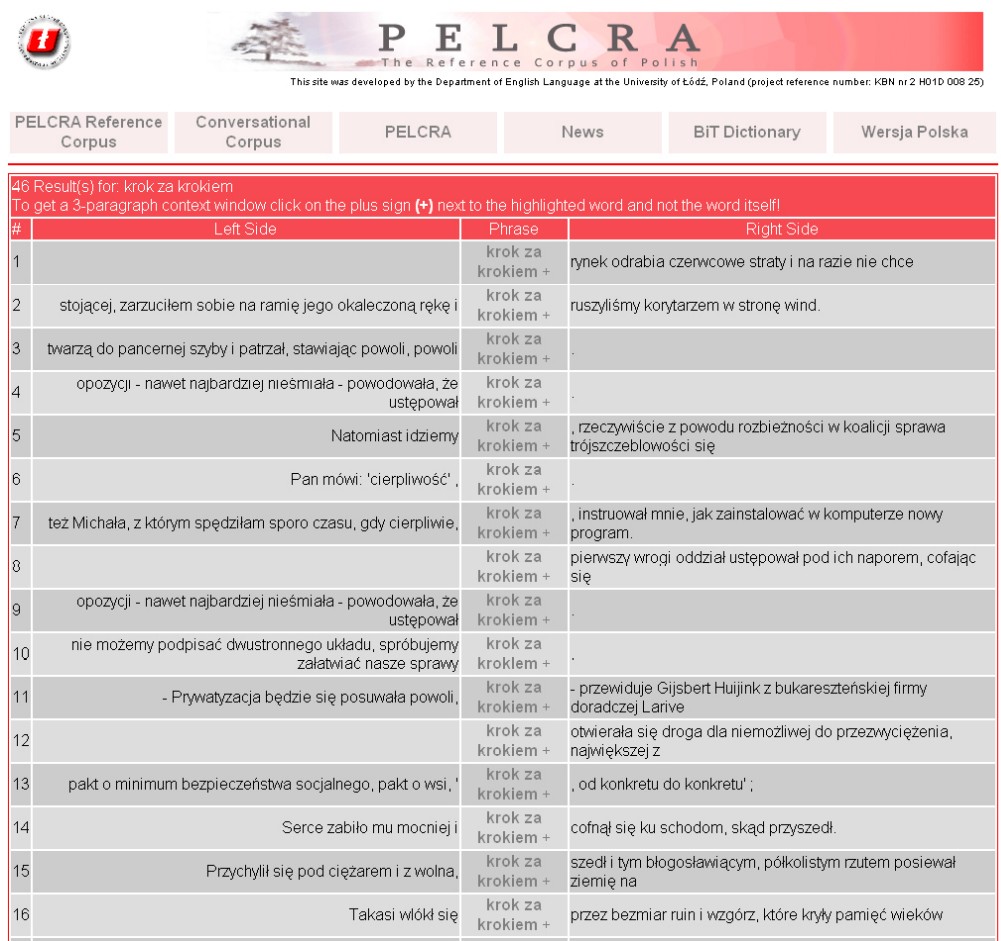
Obr. 9: Zobrazení výsledku vyhledávání fráze krok za krokem

Obr. 10: Zobrazení výsledku vyhledávání věty obsahující slova ciemna masa
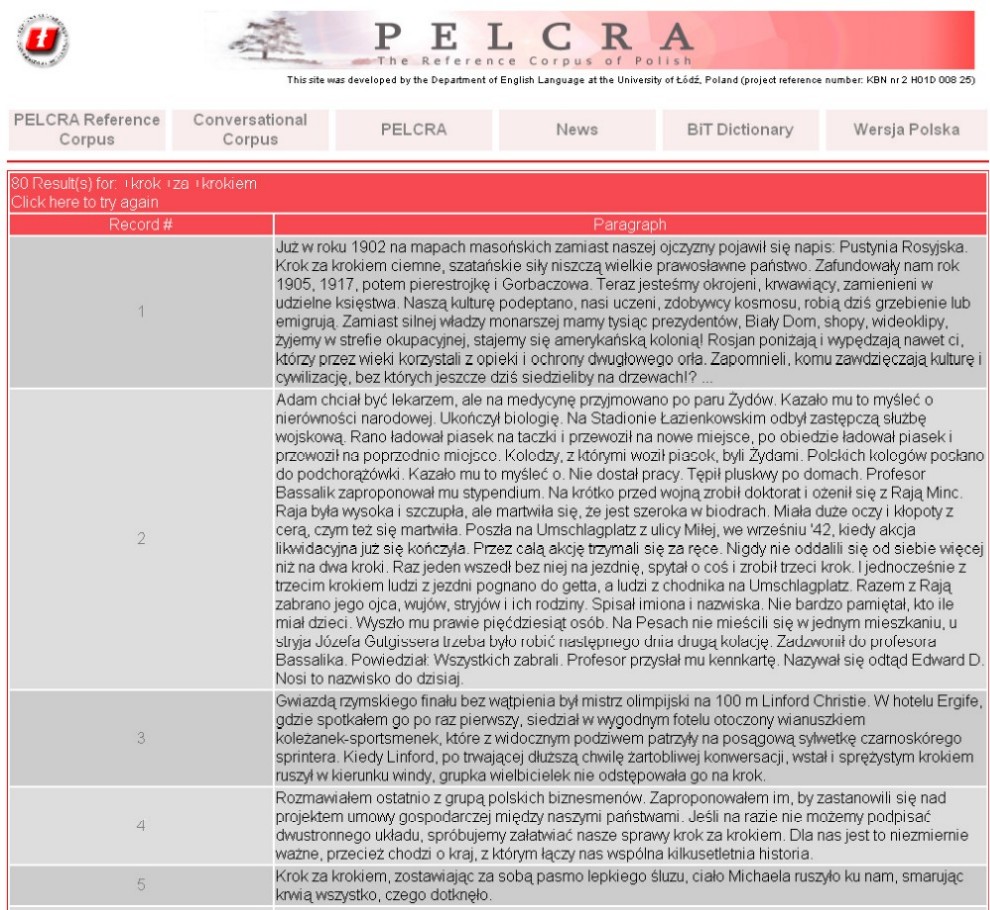
Obr. 11: Zobrazení výsledku vyhledávání odstavce obsahující slovo ciemna a neobsahující slovo masa
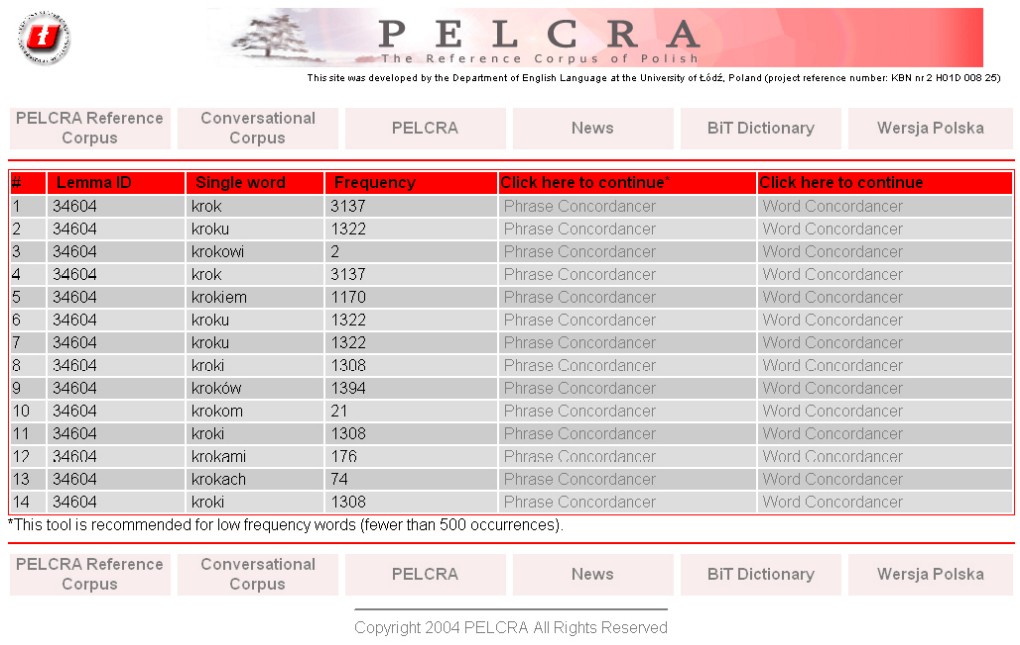
Obr. 12: Zobrazení výsledku vyhledávání všech tvarů slova krok
Závěr
Každý ze tří představených polských korpusů je něčím zvláštní. Korpus IPI PAN byl jako první polský korpus zveřejněn na internetu, Korpus jazyka polského Vědeckého nakladatelství PWN vznikl na základě jazykového materiálu sebraného pro slovníky, které nakladatelství vydává a projekt PELCRA v sobě zahrnuje několik korpusu, z nichž vedle volně přístupného Referenčního korpusu polštiny je zřejmě nejzajímavějším projektem „Polský korpsu studentů angličtiny“.
Webové prezentace jednotlivých korpsů jsou velmi různorodé, ale ve všech případech poměrně přehledné a uživatelsky přívětivé. Informací o korpusu a možností vyhledávání v něm jsou zpracovány na různé úrovni, ale vždy podávají alespoň základní přehled, který však pro náročnější uživatele nemusí být vždy dostačující.
Možnosti vyhledávání a zobrazení výsledků je ve všech zmiňovaných korpusech srovnatelné, snad jen projekt PELCRA je v tomto směru nejpropracovanější.
Uváděné korpusy jsou dobrým příkladem toho, že korpusy mohou být užitečné nejen pro lingvistické bádání, ale i např. pro přípravu učebnic k výuce cizích jazyků.
Hodnocení:
Korpus IPI PAN
Webová prezentace:Vyhledávání:
Obsah informací:
Korpus PWN
Webová prezentace:Vyhledávání:
Obsah informací:
PELCRA
Webová prezentace:Vyhledávání:
Obsah informací:
Korpus IPI PAN [online]. Warsaw : IPI PAN, c2005-2007 [cit. 2008-02-20]. Dostupné z WWW: <http://korpus.pl>.
Korpus Języka Polskiego Wydawnictwa Naukowego PWN [online]. Wydawnictwo Naukowe PWN, c1997-2008 [cit. 2008-02-21]. Dostupné z WWW: <http://korpus.pwn.pl/index_en.php>.
PELCRA : The Reference Corpus of Polish [online]. PELCRA, c2004 [cit. 2008-02-21]. Dostupné z WWW: <http://pelcra.ia.uni.lodz.pl/index_en.php>.
ŠULC, Michal. Korpusy polského jazyka. Slovo a slovesnost. 2002, roč. 63, č. 4. Dostupné také z WWW: <http://korpus.cz/doc/polsk.rtf>. ISSN 0037-7031.
Máme tu 2 komentářů
Vadí mi styl autorčina
Vadí mi styl autorčina psaní. Skoro v každé větě je užito slovo "korpus". Nepříjemně se to čte.
Korpus
Vždyť korpus je v tom článku o korpusech použit asi jen 29, čtyřačtyřicetkrát je tam korpusu. Pan George Kingsley Zipf, kdyby už nebyl 58 let mrtvý (tzn. že z jeho korpusu, tělesného, už asi moc nezbylo), by měl ale radost, že frekvence a, je, v a na je přeci jen o trošku vyšší než frekvence slova korpus ;) Pokud se i tento článek dostane do korpusu, bude to možná korpusový rekord, protože v korpusu pak bude slovo korpus zastoupeno daleko více než v jiných korpusech. Zdejší jiný článek o korpusu této autorky už okupuje první stránku v SERP na Googlu na dotaz korpus. To je úspěch, přímo můžeme říci, že korpusový úspěch!
A kdo se teď směje korpusu, ať si dá ruku na pusu!